大切なのは「圧縮」なのです。
ご飯を持ち運びたければ、おにぎりにする。旅行に行くならパッキングする。
言葉も脳で行われる概念の圧縮です。グラフも事象の圧縮であり、MPEGやMP3も映像や音響の圧縮技術です。
後者がご飯と違うのは密度の方向です。ご飯は字義通りの圧縮なのに対して、言葉やグラフは縮約であり、スカスカ化とも言える。だから上手い人も下手な人もいる。それでも日常では、人の能力を思えば手ごろで絶妙な効率化と言えるでしょう。
さて空間的なものは圧縮できても、時間方向の意味や文脈の圧縮は難しい。人の話しことば、書きことばの圧縮のことです。
日曜日の朝、子どもが起きて「パパ、晴れてるよ!」と言えばそれは遊園地に行きたいという意味だし、同じ朝でも妻が目を合わせればそれは「家事をして」の意味とみて間違いない。
(これぞ圧縮の極北、目線やしぐさによる情報伝達に勝るものはない。意図や状況をも一切の無駄なく圧縮した上、圧迫まで加えるとは。)
閑話休題、こんなひとのような対話を機械が出来るようになるとは思ってもみませんでした。
それが、GPTをはじめとするLLMでほぼ実現してしまいました。Attention(注意機構)によって長い文脈が覚えられるようになった。
そこではうまい行列演算が膨大に走り、そこに森羅万象の文章を放り込むことで、エッセンスを圧縮して抽出し、次の単語から文章まですらすら編み出すまでできるようになった。
内燃機関のように圧縮は爆発的なパワーも秘めるのでした。
まずは知識モデルとしてそれは起こりました。GPT3.5、4、を組み込んだチャットGPTとして。
そしてこの半年、いやこの一ヶ月、推論モデルが一気に進化しました。推論というからには論理の領域てす。GPT o1、o3系列が登場し、コスト1/1000というDeepSeek R1が発明され、人類は紛うかたなく次のステージに立ちました。
推論能力を高めるため、人を鍛えるかのようにAIを鍛える、さらにAI同士で高め合うところまで。囲碁のアルファ碁ZEROと同じ方法論。AI同士なので疲れを知らず、はやりの7.5時間睡眠も何のその、人の千年分の対局を数日で終えた結果、人の世界チャンピオンでさえ、いえ、その人に勝利したAIでさえ勝てない最強AIが完成しました。
それと同じことが、ことばの領域で急進行しています。
しかし、LLMは固定化が問題でした。いくら最強とは言え、変化しない種は滅びる。
この一カ月で、ついにリアルタイム自己適応学習の仕組みが発明されたようです。(前回「一緒に生活するだけで、主人友人の見方に触れて学んでいくかもしれません。(そのようなLLM / AI Agent が登場するでしょう。)」と書きましたが、その一歩目はもう登場してしまいました。)
恐らく一斉同時進行ですが、ここではサカナAIの Transformers-Squared に触れましょう。
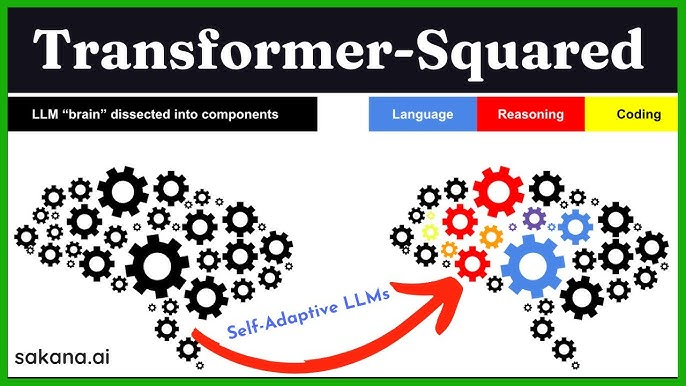
ここでの肝がまた「圧縮」なのです。SVD(SingularValueDecomposition)という、行列分解・圧縮の美しい数学手法がコアアイデアとして使われます。(私も以前、コンテクストをレコメンダーに組み込む研究で適用した手法でした1)
SVDを、推論時にタスクに応じて行列演算に適用し肝の重みだけ調整するという、言われてみれば誰もが思いつくべき手法です。
カギは、タスクごとに学習された zベクトルを強化学習により作っておくこと、推論時にはSVDの Σ (対角行列)をタスクに応じて、例えば 数学専用zベクトルで調整するメカニズムです。これを著者らは特異値微調整 (SVF)と呼んでいます。
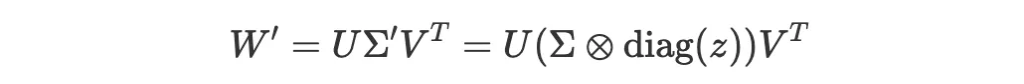
モデルが入力されたタスクをまず分析し(第1段階)、そのタスクに適した上記重み調整メカニズムを経て応答を生成する(第2段階)。
これはひょっとすると、汎用的で柔軟な適応性を持たせうるという点で、革命的なことが起きたのかもしれません。
手法はともかく、
自己適応学習ができるということは個人化LLMができるということ。すなわち自分だけのアシスタント、最適な万能教師、決して飽きさせないおしゃべり相手、ちょっと心が疲れた時にはおばあちゃんにだってなってくれる、ということ。
この続きは次回。
- 以前、コンテクストをレコメンダーに組み込む研究で適用した手法でした。いやはや20年前とは:https://patents.google.com/patent/JP2006048286A/ja ↩︎


