「誰にもわかるハイデガー」(筒井康隆)

「存在と時間」、もっとも恐ろしげな哲学書にして、人の良心・倫理の極北を示す書。
「あらゆる存在者のうちひとり人間だけが、存在の声によって呼びかけられ、<存在者が存在する>という驚異のなかの驚異を経験するのである」(ハイデガー)
このわかりにくい哲学のもっともわかりやすい解説書に出会いました。「文学部唯野教授」が’90年に行った講演録。
Bravo!筒井康隆氏。また今回解説をつけた大澤真幸氏もBravo!哲学にはユーモアをもって近づくべきと思わせる本です。
「死への先駆」と良心
巨大なハイデガー哲学のうち、ここで取り上げたいのは、良心への意志(倫理・気遣いの極大化)が「死への先駆」に最も純粋に現れるという点。
死は生きている間には経験することのできない特異点であり、死に先駆けてそれを自分事として了解するには、その「無限性の欠如」を理解しなくてはならない。これは数理論理の世界では、ゲーデルの不完全性定理により厳密に証明されたものに通ずるようですが、日々の暮らしにおいて自覚的にいることは不可能に思えます。
締切が迫ってやっと、ことに着手し、締切が過ぎたとき、純粋に良心の呵責に激しく苛まれる。よくあることです。人はそういうものなので、ハイデガーの言う「企投」※1、サルトルの言う「アンガージュマン」の態度をとるのは容易ではないのです。(あぁ青春の実存主義!)
時間性の3つの契機
「到来」(将来)と「既在」(過去)と「現成化」(現在)。死を含む未来を今ヴィヴィッドに捉え、既に在る過去と、今と言った瞬間の過去から今を瞬視する。このうち死を含む「到来」の優位のうちに3つの契機は統合されるといいます。
死は怖いのでできればその場にいたくない(笑)さらに暴力的な死の前に未了ゆえの悔恨は必然である。しかし逆に悔恨の中にこそ最も純粋な良心が生まれる。なのでそれを先取りするところから始めよう。先取りは不安によって誰にでも可能である…
🍃🍃🍃
AIによる予測モデル
話題を急に変えますが、機械学習による予測では、過去を今だとおいて、既知の未来を予測するモデルを作ります。未来は過去に含まれるという信念に基づくモデルと言えるでしょう。
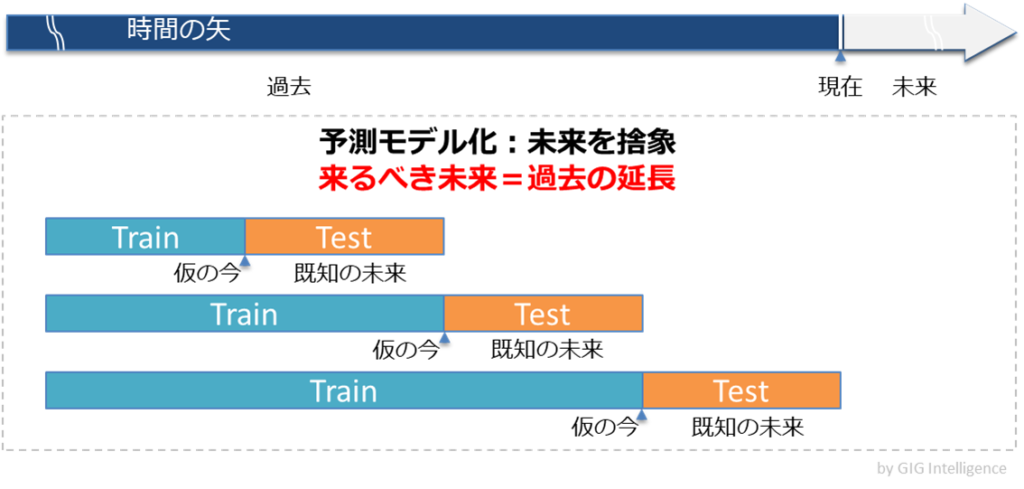
例えばデジタル広告におけるクリック予測や在庫予測、レコメンデーションにも疑いなく適用されてきた方法論です。
しかし一人ひとりの行動予測がこの方法論で高精度化できると信じるとすれば、これはハイデガーの議論とは異なる、実に凡庸なもののとらえ方であり薄っぺらな人間理解、と言わざるを得ません。※2
「現存在」とAI
もし未来がわかったら、人はそれに従う・抗うように今の行動を変えます。
問題は未来がわからないことながら、特異点としての死だけは誰にも等しく認識されている。「死への先駆」から倫理的に良心に従う意志を持つ。
未来を定めて今を見て、過去と異なる選択をするのが現存在(”Dasein”たる人間)です。
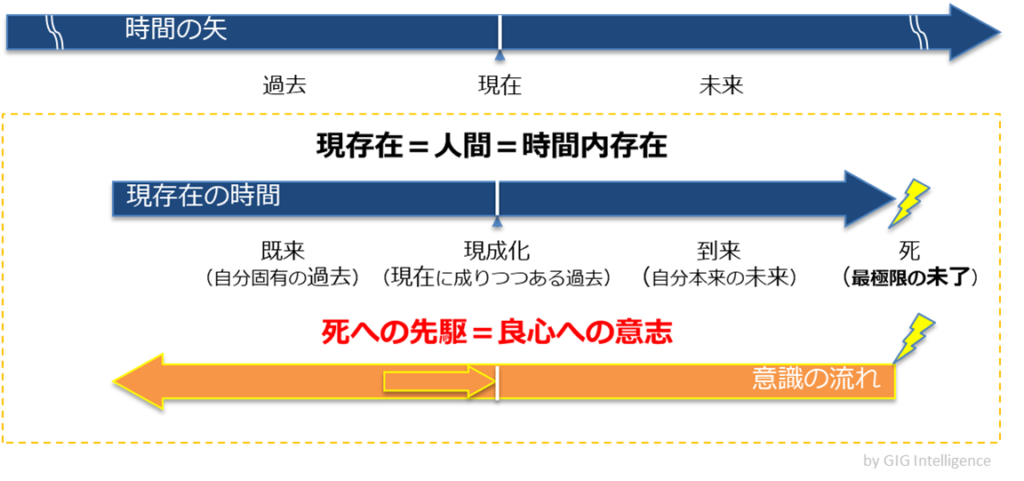
「現存在の存在は時間性である」(ハイデガー)
そんな「現存在」には、AIも歯が立たない。逆に今のAIに行動予測される人間は、現存在とは言い難いわけです。
現存在への個人化へ
実は、現状のAIによる個人化は、統計的な凡人化であって、統計的に当たればビジネスとしては充分儲かるからよいのですね。
しかし本来、個人化というならば、人の変化する能力とその方向をこそ予測すべきで、特にレコメンデーションは変化の後に必要になるモノを提示できることを目指すべきでしょう。殊にその人にとって未経験な領域は不安で一杯でしょうから。
レコメンドすべきは「到来」の1点か、受け入れるべき「現成化」か?
次回は実存主義的レコメンデーションの方法論を考えていきたいと思います。
🍃 🍃 🍃
※1, 2 第2次AI ブームの時、AIに対して猛烈な批判の声を上げ、「フレーム問題」「記号接地問題」を提起したドレイファスやサールといった哲学者たちは、ハイデガー研究者だったと知りました。
彼らの主張は、「人間は世界というものの中に「投げ込まれて」、自分を「企投」しつつ生きている。機械にはそうした生活世界がない。そんな機械が、どうやってものを考えられるのか?」というものでした。
本論は行動予測という、もっと小さなことしか言っておりません…